User Guide¶
baltrad-exchange - a multipurpose exchange engine for radar data -¶
Introduction¶
The baltrad-exchange engine is a new modernized approach of allowing exchange of radar data. Currently, the only supported format is ODIM-H5 but the allowed formats is possible to extend in the future. There are several reasons for why this engine was created but to name a few key-points:
Add more flexible routing that can route on meta-information in a file
Possibility to distribute monitored files as well as received files
Smaller (and easier) installation footprint that doesn’t require an external database
More flexible and easier configuration
Possibility to run several different instances on same server
Allow possibility to decorate a file before it is sent to a subscriber
Besides the actual server & client software it is also possible to use several APIs from within the module. Note that the namespace is bexchange and not baltrad_exchange or any other variant.
Overview¶
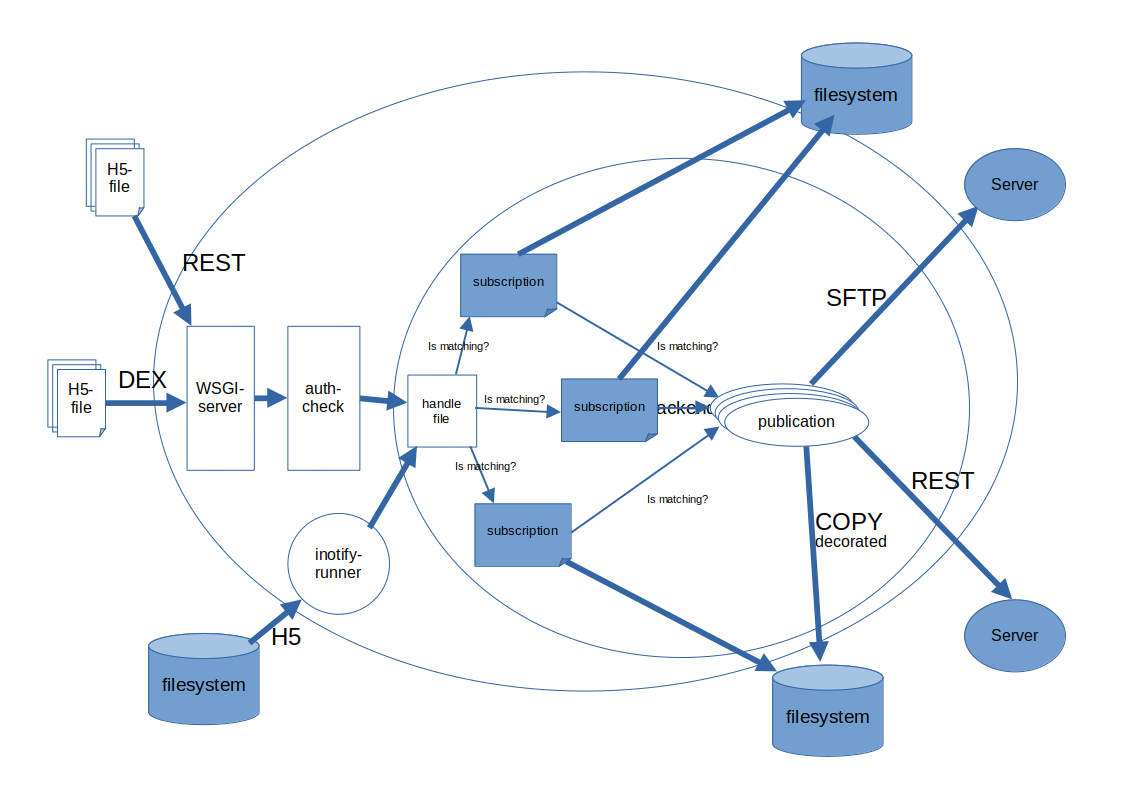
The exchange of any files can be divided into a number of different steps.
- Input
First, there is the source file that should be distributed. This file should be injected into the system some how. Either waiting for input like when receiving a file or some sort of monitoring/triggering like polling or event handling.
- Authentication
When a file is inserted into the system actively we must have some sort of authenticating that it is a valid origin. The baltrad-exchange is using public/private keys and signature handling to ensure that this is taken care of in a secure way.
- Subscriptions
When the file has passed the authentication part it is time to decide what to do with the incomming file. - First, the origin (nodename / id) of the file is verified against the subscription to know that we are expecting something from that origin. - Next the metadata is extracted from the file and matched against the subscription filter to know if this subscription should handle the file - If both of above checks has passed. Then the incomming file is stored at zero or more storages before it is published to all publications that matches the file metadata - It is also possible to put the file on a processor queue if the above checks has passed if further processing should be done within the scope of the exchange mechanism
- Publications
Since different parties want to have files distributed in various ways the publication has been divided into three different parts. The publisher, the connector and the sender. Be aware that for each matching subscription all matching publications are run which means that one file can be published more than once.
publisher is the overall spider taking care of threads, what connector to use and if the outgoing file should be modified in any way. Currently there are two publishers, the standard_publisher and the zmq publisher.
The zmq publisher doesn’t have a connection and/or sender since it’s using the internal ZeroMQ framework for communication. - connection this is the approach to use when distributing the file. For example if the file should be sent with some sort of failover, duplication, … - sender is the actual protocol to use when sending the file, like to another node, a dex-node or some sort of sftp, scp-protocol
- Runners
If a file isn’t injected into the system we need to be able to get the file into the system some other way and here is where the runners comes into action. A runner is a separate entity that uses the server backend to trigger and pass a file into the system like if it had passed the Authentication part. The runners can for example be event triggered variants like inotify. It can also be triggered variants that accepts some external trigger or scheduled variants.
Configuration¶
The basic configuration is just a property-file containing the most basic information which is specified when starting the server. In order for the system to start you won’t need any json configuration but without them the system won’t do anything.
# This is the local address the WSGI server will be listening on
baltrad.exchange.uri=https://localhost:8089
# How logging should be performed
baltrad.exchange.log.type=logfile
# The logfile to use if logfile logging is choosen. Is overridden by server options
# baltrad.exchange.log.logfile=/var/log/baltrad/baltrad-exchange-server.log
# The logfile to use if logfile logging is choosen. Can be overridden by server options.
# baltrad.exchange.log.logfile=/var/log/baltrad/baltrad-exchange-server.log
# The log id used
baltrad.exchange.log.id=baltrad-exchange
# The log level to use. All messages with priority >= log.level will be sent to the log output.
# Available are: ERROR, WARNING, INFO, DEBUG
baltrad.exchange.log.level=INFO
# Number of threads, backlog and timeout
baltrad.exchange.threads=20
baltrad.exchange.backlog=10
baltrad.exchange.timeout=10
# Restrict content size that is sent. 32MB (1024*1024*32). This should not be considered as the exact file size. It
# can also be the content size of the complete message that can be some bytes larger than actual file.
baltrad.exchange.max_content_length = 33554432
# Name of this server. Will be used when communicating with other nodes
baltrad.exchange.node.name = example-server
# Add keyczar to providers if wanted
baltrad.exchange.auth.providers = noauth, crypto
# Default crypto-variant
baltrad.exchange.auth.crypto.root = /etc/baltrad/exchange/crypto-keys
baltrad.exchange.auth.crypto.private.key = /etc/baltrad/exchange/crypto-keys/example-server.private
# It is possible to add public keys to the authenticator by adding them according to the following syntax
# baltrad.exchange.auth.crypto.keys.<node name> = <public key file name>.
# Doing this will set the nodename to <node name> and associate this node name with the provided public key
#
# This is automatically handled for the crypto private key and will associate the public key with the
# node name.
#baltrad.exchange.auth.crypto.keys.example-server = /etc/baltrad/exchange/crypto-keys/example-server.public
# If keyczar is in providers. Uncomment and create/import the keyczar private key
# baltrad.exchange.auth.keyczar.keystore_root = /etc/baltrad/bltnode-keys
# baltrad.exchange.auth.keyczar.private.key = /etc/baltrad/bltnode-keys/anders-nzxt.priv
# Comma separated list of directories where json config files are located.
baltrad.exchange.server.config.dirs = /etc/baltrad/exchange/config
# Where the odim source file can be found in rave format.
baltrad.exchange.server.odim_source = /etc/baltrad/rave/config/odim_source.xml
# The database in where some basic data is stored when performing the source-lookup
# this database doesn't need to be persisted on disk since it will be created upon started
# from the above odim_source.xml file
baltrad.exchange.server.source_db_uri = sqlite:///var/cache/baltrad/exchange/source.db
# The database where we want to store all other information. This should preferrably
# be persisted since it will contain statistics and other relevant information
# pointing to a postgres database or similar but we can use sqlite as well. This
# database will contain for example statistics and other data that should be persisted.
baltrad.exchange.server.db_uri = sqlite:///var/lib/baltrad/exchange/baltrad-exchange.db
# Note, these should only be readable by the baltrad user
# and can be created using the following command.
# openssl req -nodes -new -x509 -keyout server.key -out server.cert
baltrad.exchange.server.certificate = /etc/baltrad/exchange/etc/server.cert
baltrad.exchange.server.key = /etc/baltrad/exchange/etc/server.key
# Statistics
# It is possible to accumulate statistics from the operation. Most of this configuration is performed
# per subscription / publisher / ... and all other cfg-entries that support this functionality
# However, there are some general statistics that is configured from this section.
# This data will be (unless otherwise configured) stored in the database pointed to by baltrad.exchange.server.db_uri
# Keeps track of all incomming files. Will be stored with spid == server-incomming for each source/origin
baltrad.exchange.server.statistics.incomming=false
# Keeps track of all duplicate files. Note, this is from a general point of view. Will be stored with spid == server-duplicate for each source/origin
baltrad.exchange.server.statistics.duplicates=false
# Each incomming file will be stored as one separate entry so that it is possible to
# calculate average process times and other relevant performance numbers.
baltrad.exchange.server.statistics.add_individual_entry=false
# Each incomming file will be associated with a total processing time to be able to check
# if there are any performance issues. This will not result in a total, just individual entries.
baltrad.exchange.server.statistics.file_handling_time=false
# If you need to load different objects from paths that are not in the standard PYTHONPATH,
# then this configuration entries can be used to add paths to the sys.path.
# Sequenced from 1.. and when first number in sequence is missing no more atempts will be done.
# baltrad.exchange.server.plugin.directory.1 = /etc/baltrad/exchange/plugins
During startup all config.dirs will be traversed and all files ending with .json will be processed and possibly parsed. Each json-file should be defined like
{"<keyword>":{
}
}
Where the <keyword> is one of the following types:
subscription
storage
publication
runner
processor
Whenever a json file is read and the backend identifies one of the above keywords the object is created to support that configuration. Each of these keyword configurations will be explained later on.
Templates¶
To simplify the exchange and setup of the system, there is the possibility to use a template (or templates) to generate the subscription and publication that will be used to configure the exchange. The template contains the necessary parts which are used when the subscription and publication is generated.
The first part is the publication part that contains the sender type and the type of publisher that should be used. Currently, only the rest_sender is supported as template and obviously only crypto which is the encryption method used by the rest-sender. The other section is the filter that will be used for matching files. This part will be put into both the publication and the subscription section.
When the template has been created it is possible to use the baltrad-exchange-config program to generate both publication and subscription artifacts. The default location for the template is /etc/baltrad/exchange/etc/exchange-template.json. If you want to use several different templates you can instead specify the template file to use by specifying –template=<template file name>.
The publication that should be placed in the json configuration folder is created by issuing the following command.
%> baltrad-exchange-config create_publication --template=exchange-template.json \
--desturi=https://remote.baltrad.node --name="pub to remote node" --output=remote_node_publication.json
When the publication has been created the required modifications should be performed before putting it in the json config folder.
A subscription that should be sent to a subscriber is created in a similar way.
%> baltrad-exchange-config create_subscription --template=exchange-template.json \
--output=remote_node_publication.json
The output from this will be a tar ball containing the public key and the subscription configuration. This bundle should be sent to the subscriber using email or some other distribution mechanism. The user on the other hand should unpack this file and put the files at the appropriate locations. If the subscriber wants to limit the files received, then the publisher should be made aware of this so that they can limit the outgoing files.
Subscriptions (subscription)¶
A subscription defines what should be allowed into the system and the basic operations that should be performed on the data that arrives. A subscription contains the following parts:
- id
In some cases it is nessecary to identify the subscription. For example when tunneling incomming files to a particular publisher.
- active
If the subscription is active or not. It can be set to false to be able to keep subscription configuration without using it.
- storage
A list of zero or more named storages
- statdef
A list of definitions for generating statistics. This should be a list containing a number of statistic plugin definitions. [{“id”:”stat-subscription-1”, “type”: “count”}] id is the spid this will be stored with in the database type defines if how the statistics should be stored. add == only add entries to statentry, count == only update count or both == do both
- filter
A filter “bdb-style” that is used to match the files metadata to decide if this subscription is interested in the incomming file or not.
- allow_duplicates
The software identifies all H5-files (and possibly other formats in the future) by generating a checksum from the metadata. This checksum will be stored internally for a while to be able to identify duplicates. Then it is up to a subscription to decide if it should allow duplicates or not. Default behaviour is always to not allow duplicates but in certain scenarios it might be necessary.
- allowed-ids
A list of allowed ids that identifies the origin. This will automatically be extended with the nodenames of the allowed nodes. It can also be identifying a runner and other internal ids.
- cryptos
This actually defines an origin that is using the REST-protocol by defining the crypto used by that origin. All cryptos will be registered in the authentication manager and when a file arrives the signature will be validated in the auth-check before the file is handled.
The subscription will however not decide where a file should be published or if it should be processed. Instead all files that passes the filter and allowed-ids check will first be distributed to the publishers and then to the processors. If it is nessecary to distribute/publish a file directly it can be done by implementing a distributed storage that handles this. Keep in mind that this will require some threading and other considerations since the subscription handling should not be allowed to block waiting for time consuming operations since it will starve the WSGI-servers thread pool.
{
"subscription":{
"id":"local subscription",
"active":true,
"storage":["default_storage"],
"statdef": [{"id":"stat-subscription-1", "type": "count"}],
"filter":{
"filter_type": "and_filter",
"value": [
{ "filter_type": "attribute_filter",
"name": "_bdb/source_name",
"operation": "in",
"value_type": "string",
"value": ["sehem","seang", "sella"]
},
{ "filter_type": "attribute_filter",
"name": "/what/object",
"operation": "in",
"value_type": "string",
"value": ["SCAN","PVOL"]
}
]
},
"allow_duplicates":false,
"allowed_ids":["anders-other"],
"cryptos":[
{
"auth":"keyczar",
"conf":{
"nodename": "anders-nzxt",
"pubkey":"/opt/baltrad2/etc/bltnode-keys/anders-nzxt.pub"
}
},
{
"auth":"crypto",
"conf":{
"nodename": "anders-silent",
"creator": "baltrad.exchange.crypto",
"key": "-----BEGIN PUBLIC KEY-----\nMIID<.....full public key in PEM format.....>==\n-----END PUBLIC KEY-----",
"_comment_":"Instead of using 'key', it is possible to specify a file. If the pubkey is not pointing to an absolute path it will be using the keystore roots as well",
"pubkey":"anders-silent.public",
"keyType": "dsa",
"type": "public"
}
}
]}
}
The subscription contains two very important parts. First the filter, this will ensure that only files that are of interest will be managed. The filter syntax is currently according to the baltrad-db query syntax and hence the “_bdb/” identifier is used for internal metadata. The second part if a combination of allowed_ids and cryptos. When system is starting up, all cryptos in all subscriptions are processed and registered in the authentication manager together with the nodename. The node names are added to the list of allowed_ids each subscription has. Then only files sent from an id that is in list of allowed ids will be allowed.
Currently, the only allowed cryptos are keyczar (for DEX-compatibility) and the internally used crypto which is just using plain public/key-signature handling.
As can be seen in the above example, there is a storage named “default_storage” that this subscription expects the files to be stored in.
Storages (storage)¶
The storages are locations where files should be placed and are referred to by the subscriptions. Typically you would only have a few different storages. For example on the file system, in a database or in an archive.
{
"storage": {
"class":"bexchange.storage.storages.file_storage",
"name":"default_storage",
"arguments": {
"structure":[
{"object":"SCAN",
"path":"/tmp/baltrad_bdb",
"name_pattern":"${_baltrad/datetime_l:15:%Y/%m/%d/%H/%M}/${_baltrad/source:NOD}_${/what/object}.tolower()_${/what/date}T${/what/time}Z_${/dataset1/where/elangle}.h5"
},
{"path":"/tmp/baltrad_bdb",
"name_pattern":"${_baltrad/datetime_l:15:%Y/%m/%d/%H/%M}/${_baltrad/source:NOD}_${/what/object}.tolower()_${/what/date}T${/what/time}Z.h5"
}
]
}
}
}
The above storage-mechanism (baltrad.exchange.storage.storages.file_storage) is probably the one that is going to be used the most. It gives the user a possibility differentiate between what/object types and store them with different names in different places. This storage-class also provides the chance of using metadata naming which is quite powerful when saving the files.
There is another storage that can be used for monitoring incomming files and rotate them so that the most recent files always are kept. The files will all be stored in the same folder and the maximum limit is to keep 500 files stored at any given time. This value can be lower but not above 500.
{
"storage": {
"class":"bexchange.storage.storages.simple_rotating_file_storage",
"name":"rotating_file_storage",
"arguments": {
"folder":"/tmp/rotating",
"number_of_files":50
}
}
}
Naming¶
The metadata namer is a separate class that can be used when a string should be created from the metadata. The ${..} is used as a placeholder for an ODIM H5 metadata attribute to retrive the value of the metadata attribute. For example ${/what/object} will give SCAN/PVOL/.. Then there are a few unique placeholder variables that doesn’t exist in the metadata of a ODIM H5 file but are very useful.
- _baltrad/source:<ID>
Since what/source can be incomplete, this will return the specific <ID> after the source has been identified. E.g. _baltrad/source:WMO, _baltrad/source:NOD. If source not could be identified, “undefined” is returned.
- _baltrad/source_name
Since what/source can be incomplete, this will return the name of the source after the source has been identified. Typically it is the NOD. If source not could be identified, “undefined” is returned.
- what/source:<ID>
Grabs the <ID> directly from what/source and returns it. Note, if source is incomplete this will return “undefined”
- /what/source:<ID>
Grabs the <ID> directly from /what/source and returns it. Note, if source is incomplete this will return “undefined”
- **_baltrad/datetime(:[A-Za-z0-9\-/: _%]+)?**baltrad
For creating datetime strings from the what/date + what/time. The dateformat is same as provided in the datetime class. For example if you want to specify a date as 2022/11/03/12/04, the you use the following description ${_baltrad/datetime:%Y/%m/%d/%H/%M}.
- _baltrad/datetime_u:([0-9]{2})(:[A-Za-z0-9\-/: _%]+)?
In some cases you might want to have minute-intervals. For example a directory structure where you want all files between minute 1-15 to be placed in a folder with 15 as minutes. This can be achieved by specifying ${_baltrad/datetime_u:15:%Y/%m/%d/%H/%M} and the folders will have a minute part that is either 00,15,30 or 45. This function will also wrap so that if what/time has minutes between for example 46-60, then these will be placed in next hours 00-minute folder.
- _baltrad/datetime_l:([0-9]{2})(:[A-Za-z0-9\-/: _%]+)?
This placeholder almost behaves like _baltrad/datetime_u with the exception that it will lower the minute interval instead. This means that all files within minute 0-15 will be put in 00, between 15-30 in 15 and so on. Syntax is almost identical ${_baltrad/datetime_l:15:%Y/%m/%d/%H/%M}
The naming functionality also provides something that can be called suboperations which allows the manipulation of the values that are returned by the placeholders. These are used directly on the placeholder. For example ${what/source:CMT}.tolower(). They can also be chained like ${what/source:CMT}.tolower().toupper(1).
Currently the supported suboperations are:
- tolower([beginIndex[,endIndex]])
changes the string to lower case. If beginIndex is specified the string gets lower case after specified beginIndex until end or endIndex if specified.
- toupper([beginIndex[,endIndex]])
changes the string to upper case. If beginIndex is specified the string gets upper case after specified beginIndex until end or endIndex if specified.
- substring(beginIndex[,endIndex])
returns a substring from beginIndex to end or endIndex if specified.
- replace(matchstr, replacementstr)
replaces all occurances of matchstr with replacementstr
- trim()
Trims both left and right side of the string from any white spaces.
- ltrim()
Trims the left side of the string from any white spaces.
- rtrim()
Trims the right side of the string from any white spaces.
- interval_u(interval[,limit])
Do not use, under development
- interval_l(interval)
Do not use, under development
With the above knowledge, assuming that a scan with elevation angle=0.5 arrives from sella, with /what/date=20221103 and /what/time=220315 then the following expression ${_baltrad/datetime_l:15:%Y/%m/%d/%H/%M}/${_bdb/source:NOD}_${/what/object}.tolower()_${/what/date}T${/what/time}Z_${/dataset1/where/elangle}.h5 will result in 2022/11/03/22/00/sella_scan_202211032203_0.5.h5.
Extending namers¶
It is possible to extend the naming functionality with custom tags by subclassing bexchange.namer.metadata_namer_operation. At the time of writing this documentation baltrad exchange provides one custom namer that can be added when creating the names.
${_baltrad/opera_filename} bexchange.namer.opera_filename_namer¶
This is a custom filename namer that can be used to generate filenames following the opera naming convention. The namer configuration should be defined as
{
"naming_operations": [
{
"tag":"_baltrad/opera_filename",
"class":"bexchange.naming.namer.opera_filename_namer",
"__comment__":"Follows Opera naming, lowest angle=A and so on..",
"arguments": {
"namer_config":{
"default":{"elevation_angles":[0.5, 1.0, 1.5, 2.0, 2.5, 4.0, 8.0, 14.0, 24.0, 40.0, 1.25]},
"sella":{"elevation_angles":[0.5, 1.0, 1.5, 2.0, 2.5, 4.0, 8.0, 14.0, 24.0, 40.0, 1.25]}
},
"__filename__":"/..../opera_namer_config.json"
}
}
]
}
Since elevation angles are getting defined using letters the order of elevation angles where A is lowest elevation angle, B second lowest and so on, all elevation angles for a site has to be specified in order to know what letters that should be used. Either the entry “namer_config”:{…} can be defined directly in the json configuration file for the class using the opera filenamer tag or else you can have a globally available config file containing the radar sources. This file should also be defined using “namer_config”:{….} but it should be placed in a separate file that is referenced in the arguments when creating the opera_filename_namer.
{
"namer_config":{
"default":{"elevation_angles":[0.5, 1.0, 1.5, 2.0, 2.5, 4.0, 8.0, 14.0, 24.0, 40.0, 1.25]},
"sella":{"elevation_angles":[0.5, 1.0, 1.5, 2.0, 2.5, 4.0, 8.0, 14.0, 24.0, 40.0, 1.25]}
}
}
Publications (publication)¶
Whenever a subscription has approved an incoming file, this file will be posted to all publications which in turn will have to decide if the file should be distributed or not depending on the file content. Obviously, this might cause some problems if not configuring the system properly since if more than one subscription approves the same file, then this file might be sent twice. In the same way, if a publication filter is to generic files might be sent more than once. However, if for some reason, a tunnel behaviour is required between the subscriber and publisher it is possible to configure a subscription_origin for that publication.
A publication uses a publisher that will take care of the sending the file. Each publisher should support handling of connections, filters and decorators. Currently, there is only one publisher distributed in baltrad-exchange and that is the baltrad.exchange.net.publishers.standard_publisher. This publisher uses a threaded producer/consumer approach.
- filters
The filters are working in the same way as they are for subscriptions and are used for matching.
- connections
A connection will take care of distribution of the file to it’s destination. A connection is usually using one or more senders to distribute the file and will be explained further down.
- decorators
Are used to modify the outgoing file in some way. The decorators are most likely plugins using ODIM-H5 manipulating software like rave or h5py.
- subscription_origin
If tunnel between subscription and publication is required, this entry can be set with the subscription ids to react to.
The basic structure of a publication configuration looks like
{
"publication":{
"name":"Send file to localhost",
"class":"bexchange.net.publishers.standard_publisher",
"extra_arguments": {
"threads":2,
"queue_size":50,
"statistics_ok": {"id":"stat-publication-ok", "type": "both"},
"statistics_error": {"id":"stat-publication-error", "type": "count"}
},
"active":false,
"connection":{
},
"filter":{
},
"decorators":[
]
}
}
The bexchange.net.publishers.standard_publisher class takes a number of arguments.
- threads
Number of threads that should consume the queue
- queue_size
How many items that should be allowed in the back queue before they are removed
- statistics_ok
- A definition for generating statistics when publication went ok. This should be a statistics plugin definition: [{“id”:”stat-subscription-1”, “type”: “count”}]
id is the spid this will be stored with in the database type defines if how the statistics should be stored. add == only add entries to statentry, count == only update count or both == do both
- statistics_error
- A definition for generating statistics when publication failed. This should be a statistics plugin definition: [{“id”:”stat-subscription-1”, “type”: “count”}]
id is the spid this will be stored with in the database type defines if how the statistics should be stored. add == only add entries to statentry, count == only update count or both == do both
`sing a simple_connection which only supports one sender. The sender used will be a baltrad.exchange.net.senders.rest_sender which uses the “stock” baltrad-exchange exchange protocol.
When the publisher sends a file to the simple_connection it will be passed to the sender that will atempt to send the message to the destination.
"connection":{
"class":"bexchange.net.connections.simple_connection",
"arguments":{
"sender":{
"id":"rest-sender 1",
"class":"bexchange.net.senders.rest_sender",
"arguments":{
"address":"https://some.remove.server:8443",
"protocol_version":"1.0",
"crypto":{
"libname":"crypto",
"nodename":"anders-silent",
"privatekey":"/projects/baltrad/baltrad-exchange/etc/exchange-keys/anders-silent.private"
}
}
}
}
}
If the sender for some reason fails to send the data to it’s intended target, this publication will be failed. Now, assume that we know that the destination server is known to be under heavy load at times and that there is a backup sftp-server where we can put the files whenever the destination server is unavailable. In that case we can use a failover_connection instead. This connection type allows a list of senders that will be executed in sequence until the first sender succeeds.
"connection":{
"_comment_":"This is a connection used when publishing files to a dex server",
"class":"bexchange.net.connections.failover_connection",
"arguments":{
"senders":[
{
"id":"rest-sender 1",
"class":"bexchange.net.senders.rest_sender",
"arguments":{
"address":"https://some.remove.server:8443",
"protocol_version":"1.0",
"crypto":{
"libname":"crypto",
"nodename":"anders-silent",
"privatekey":"/projects/baltrad/baltrad-exchange/etc/exchange-keys/anders-silent.private"
}
}
},
{ "class":"bexchange.net.senders.ftp_sender",
"arguments": {
"uri":"sftp://sftpuploader@some.remove.server/dex_failover/${_baltrad/source:NOD}_${/what/object}.tolower()_${/what/date}T${/what/time}Z_${/dataset1/where/elangle}.replace('.','_').h5",
"create_missing_directories":true
}
}
]
}
}
The following connections are currently available:
- bexchange.net.connections.simple_connection
Simple connection that only takes one sender and if the sender fails the transmission is failed.
- bexchange.net.connections.failover_connection
Takes a list of senders and will try the senders sequentially until the first sender succeedes. If all sender fails, then transmission is failed.
- bexchange.net.connections.backup_connection
Takes a list of senders and will send to all senders regardless if the previous one succeeded or failed.
Senders¶
The senders are protocol specific and ensures that the data is sent correctly and if applicable, in a secure way. There are several predefined ways to send files. Since each sender has it’s own set of arguments to be initiated you find examples on how to use them in the etc-catalogue.
- bexchange.net.senders.storage_sender
Publishes a file using file storages. This is very useful if you want to decorate a file before it is put on the storage.
- bexchange.net.senders.dex_sender
Legacy DEX communication sending files to old nodes
- bexchange.net.senders.rest_sender
Sends a file to another node that is running baltrad-exchange. The rest sender uses the internal crypto library for signing messages which currently supports DSA & RSA keys. DSA uses DSS, RSA uses pkcs1_15.
- bexchange.net.senders.sftp_sender
Sends files over sftp
- “arguments”: {
“properties”:”<property filename>”, “uri”:”sftp://<username>:<password>@<hostname>:<port>/<folder_and_filename>”, “create_missing_directories”:false, “tmppattern”:[“^”,”.”]
}
properties can be used in the URI, for example ${_property:this.username}. In this case, it will check the properties for this.username and replace that part in the uri.
uri is what it sounds like, for sftp_sender the scheme is sftp:
tmppattern in some situations the file has to be uploaded with some identifier before it is renamed to wanted name in uri. The pattern should always be find-str and then replacement str. and the length of the list should be evenly divided by two so the format can be defined as [<re match>, <replacement>]*
- bexchange.net.senders.scp_sender
Publishes files over scp
- bexchange.net.senders.ftp_sender
Publishes files over ftp
- bexchange.net.senders.copy_sender
Publishes files by copying them. It uses it’s own metadata namer.
Decorators¶
The decorators are the baltrad exchange engines way to allow you to modify files before publishing them. For example if you only want to publish a few parameters, if you want to add some important text in a how-section or maybe convert the ODIM-version to a different one. At the moment, there aren’t any decorators distributed with the baltrad-exchange engine. Below is an example on how a decorator that removes all quantities except the ones that was configured.
from __future__ import absolute_import
from baltrad.exchange.decorators.decorator import decorator_manager, decorator
import _raveio, _rave, _polarvolume, _polarscan
from tempfile import NamedTemporaryFile
import shutil
class keep_quantities_decorator(decorator):
"""Removes all quantities in a volume or scan except the ones specified.
"""
def __init__(self, backend, alldiscard_on_noneow_discard, quantities=["DBZH","TH"], age=60):
super(keep_quantities_decorator, self).__init__(backend, discard_on_none)
self._quantities = quantities
def decorate(self, inf, meta):
try:
a = _raveio.open(outf.name).object
if _polarvolume.isPolarVolume(a) or _polarscan.isPolarScan(a):
a.removeParametersExcept(self._quantities)
newf = NamedTemporaryFile()
rio = _raveio.new()
rio.object = a
rio.save(newf.name)
newf.flush()
return newf
except:
import traceback
traceback.print_exc("Failed")
return None
The decorator is in turn configured in the publisher as
"decorators":[
{ "decorator":"rave_be_decorator.keep_quantities_decorator",
"discard_on_none":true,
"arguments":{
"quantities":["DBZH", "VRADH", "TH"],
"age":10
}
}
]
Runners (runner)¶
A runner is something that is running on the side of the actual file handling taking care of miscellaneous tasks. The two most typical runners are used for getting aware of when files are available for injection into the system like an active or triggered subscription. The runners have a different entrance to the system by going directly to the subscription-handling in the backend without any authentication. Currently, there are two runners implemented in the exchange server but like with the rest of the system it is easy to extend with new runners.
- bexchange.runner.runners.inotify_runner
The inotify runner is used to monitor folders and trigger “store” events. It is run in a separate thread instead of beeing created as a daemon-thread since all initiation is performed in the main thread before server is started.
- bexchange.runner.runners.triggered_fetch_runner
A triggered runner. This runner implements ‘message_aware’ so that a json-message can be handled. This runner is triggered from the WSGI-process and as such is using the WSGI-servers thread pool. TODO: Implement this as a producer/consumer thread to avoid any possibility to starve the WSGI-thread pool.
The fetcher runner will react on a trigger message and then use a protocol-specific fetcher to retrieve files from a server host in some way. Currently there is support for the following fetchers.
bexchange.net.fetchers.sftp_fetcher - Fetches files from host using sftp
bexchange.net.fetchers.scp_fetcher - Fetches files from host using scp
bexchange.net.fetchers.ftp_fetcher - Fetches files from host using ftp
bexchange.net.fetchers.copy_fetcher - Fetches files from host using file copy
- bexchange.runner.runners.statistics_cleanup_runner
The statistics cleanup runner is used for ensuring that the statistics data tables gets too large. The configuration of the cleanup runner is done using two attributes, interval and age. The interval is specified in minutes telling the system how often the routine should be executed. Age is specified in hours and all entries older than specified number of hours will be removed.
{
"runner":{
"_comment_":"Cleanup of statistics database run as a runner.",
"active":true,
"class":"bexchange.runner.runners.statistics_cleanup_runner",
"extra_arguments": {
"name":"statistics_cleanup_runner",
"interval": 1,
"age":48
}
}
}
Processors (processor)¶
The processors can be seen as a combination of runners and decorators these are triggered during the subscription validation process in the same way as a publisher. That means that all processors will be notified about a file when it has passed the subscription matching. The processor is intended for building products from incoming data in various ways in an asynchronous way and is not allowed to be blocking. This means that when a file has been passed to the processor, the processor should pass it on to a queue of some sort and return immediately. The exchange server expects no response and will. Instead it is up to the processor to ensure that the resulting product is taken care of, for example by notifying the exchange server that there is a file available.
Installation¶
The easiest way to install the software is if you are using a RedHat 8 based distribution since you in that can install the software from the prebuilt packages. Other distributions requires installation from source for both bdb and hlhdf.
Installing from RPM¶
First, you should enable the baltrad package repository which is done as super user.
%> cd /etc/yum.repos.d/
%> wget http://rpm.baltrad.eu/CentOS/8/latest/baltrad-package-latest.repo
%> dnf update
Then you should install some dependencies before installing the baltrad-exchange server.
%> sudo dnf install python3-lockfile python3-pycryptodomex python3-numpy
%> sudo dnf install python3-paramiko python3-scp
%> sudo dnf install baltrad-db*
Finally you should install the baltrad-exchange server
%> sudo dnf install baltrad-exchange
Installation of software from github¶
If you want to create a local installation directly from github where the code resides you can use pip for that.
First you will have to install all dependencies, either using the distributions packages or else you can use pip for that as well. In either case you will have to install several components like lockfile, pycryptodomex, numpy, paramiko, scp, baltrad bdbcommon & bdbclient as well as hlhdf or h5py.
The next step to do is to to create a virtual environment and install the baltrad software. Change to a suitable location, for example /opt/baltrad
Then you can install the software by running the following commands.
Then you should configure the system to your likings.
Preparing for development¶
The installation process from source can be used for either running the server or for development purposes.
The first step that will be required is to get all dependencies in place. Either using prebuilt packages or directly from source. The following python packages will be needed lockfile, pycryptodomex numpy, paramiko, scp, baltrad-db bdbcommon & bdbclient and hlhdf.
Fetch the baltrad-exchange engine by downloading it from github as your ordinary user
%> cd /projects
%> git clone https://github.com/baltrad/baltrad-exchange.git
%> cd baltrad-exchange
The easiest way to start developing in baltrad-exchange is to create a virtual environment that will be used for local installations and tests.
%> python3 -m venv --system-site-packages env
%> . env/bin/activate
With the virtual environment created you can just install the baltrad-exchange software into your own environment by typing
%> python3 -m pip install .