 |
Frequently Asked Questions and User Guide
|
|
Frequently Asked Questions and User Guide
|
CONTENTS
BALTRAD is many things, and it can be a bit confusing if you use the name out of context. Some of our bosses wanted us to have separate names for different contexts, and we have tried (but failed so far) to come up with a catchy name for the software system. BALTRAD is the following things:
BALTRAD is a project partly funded by the European Union's Baltic Sea Region Programme. To our knowledge, it is the first time that European money is being used for establishing a weather radar network not as a prototype or proof-of-concept, but as a real-time element of regional infrastructure. The BALTRAD main-stage project has taken place between February 2009 and January 2012.
BALTRAD is a cooperation, a partnership with the following partners:
Swedish Meteorological and Hydrological Institute
Finnish Meteorological Institute
Institute of Meteorology and Water Management, Poland
Latvian Environmental Geology and Meteorological Centre
Danish Meteorological Institute
Republican Hydrometeorological Centre, Belarus
Finnish Radiation and Nuclear Safety Authority
Estonian Meteorological and Hydrological Institute
Recently, this partnership has been expanded to include:
German Weather Service
Lithuanian Hydrometeorological Service under the Ministry of Environment
Nowergian Meteorological Institute
Department of Civil Engineering, Aalborg University, Denmark
Aarhus Water A/S, Denmark
BALTRAD is a weather radar network, operating in real-time, exchanging data among members of the partnership and generating products using a common "toolbox" of data processing algoithms.
BALTRAD is a software system that contains all the functionality required to create and operate an efficient and modern international weather radar network. The software has been created by and for the partnership, but also for others who are interested in it.
BALTRAD used to be a research radar network created to support the Baltic Sea Experiment, Europe's contribution to the Global Energy and Water Cycle Experiment, under the auspices of the World Meteorological Organization. This old network still exists but is running on autopilot with no development.
BALTRAD+ is an extension-stage project stemming from the BALTRAD project. The source of funding is the same, whereas the partnership has grown to comprise 13 partners in 10 countries. Both geographical and thematic scopes have been extended from the main-stage project.
In BALTRAD+ we are including radar data from Germany, Lithuania, and Norway into the network, we are transferring our system to X-band in support of applications at the municipal scale, we are continuing our focus on improving data quality in support of the users, and we are making our overall system truly operational. We are also welcoming cooperation with other organizations wishing to use our software or joining the cooperation.
Yes, all software delivered by the project is Open Source, free for anyone to use, according to the GNU Lesser General Public License (LGPL). See http://www.gnu.org/licenses/ for more information.
http://git.baltrad.eu/manual/releases.html
The developers. The software is modular, and different developers have contributed different parts. Each developer retains the IPR to the code they have contributed. This applies to project partners and anyone else who wants to get involved.
Yes, the LGPL license allows commercial use.
The BALTRAD system allows exchange of weather radar data, data processing, and all the things you should need in support of these two main tasks. The exchange mechanisms are peer-to-peer; you can control who you want to exchange data with, and you can also control what you want to exchange with whom.
The data processing functionality is optional. It generates products using algorithms that you won't find in other systems. This is for two reasons:
We have developed our software for Linux, and to our knowledge BALTRAD software is running on Ubuntu, Debian, Red Hat Enterprise, and CentOS. Most of our packages run on Mac OS X too, although the complete suite hasn't been validated on it yet. Our software may run on proprietary flavors of UNIX, but we have conducted no development or testing on any.
As soon as we started the BALTRAD project, we discovered that the various developers scattered throughout the region couldn't agree on a single language to use. So we let ourselves be inspired by Google who use three languages. The ones we have chosen are C/C++, Java, and Python. At one stage of the project C++ dropped in favour for Python and Java in one of our core subsystems, so C++ is no longer part of the core system.
From revision 3.0 we have dropped Python 2.7 support in favour for Python 3.6 since Python 2.7 soon will reach it's end of line.
We also use some other scripting tools for specific purposes. For example, Groovy scripting (based on Java) is used for prototyping well-defined tasks.
No, our system is designed primarily for real-time operation, and it doesn't make sense to manage huge volumes of data in such an environment. We also recognize that different organizations have different archiving policies and systems, so we had no problem deciding that we didn't want to reinvent this wheel. You can use our system to output data in a way that works with your archiving routines.
Our software is for anyone with a weather radar or weather radar data. While our main focus has been on creating a system for real-time fully-automated use, you can use parts of our software interactively, off-line, in research mode. This is intended to facilitate and accelerate the developement process, where new data processing functionality can be rapidly prototyped and then integrated into a full system context with a minimum of hassle. So, with this in mind, we think and hope that our software will appeal to radar owners/operators (e.g. national meteorological and hydrological services), and developers/researchers in government and university environments.
No, running the radar itself is still the owner's responsibility, and there is no functionality in our software for connecting to any radar with the intention to control it.
However, in the opposite direction, we make it easier for the radar to output data in a standardized way so that our system can take care of them efficiently.
BALTRAD software is portable, open, and transparant. That means that the Open Source code lets you understand what it actually does.
The BALTRAD system facilitates data exchange, and our data-processing paradigm puts its toolbox in your hands where you can process data locally according to your needs. You are not dependent on someone else processing data for you elsewhere. Using BALTRAD, you process your data together with others' data on equal terms. The quality of the results should be higher and more harmonized.
Our system is built to scale to manage continental-size radar networks. It will not cause system performance bottlenecks.
Using BALTRAD software puts you in touch with a community, if you want to be part of it. In some places, there are very few people with weather radar expertise, so being part of a community can connect to a critical mass of knowledge and help move the state-of-the-art forward more rapidly. We all benefit from this.
There are no license fees associated with using this software, so such costs can, in principle, be saved.
We would like to think that the quality of our data processing algorithms is the highest available today. That's quite a claim, but it's also a proper level of ambition for a partnership that wants to be on the cutting edge.
The second part of the question is "... and if so, lay it on me!"
People benefit more from working together than from working alone. There are very few people with world-class radar meteorological and software engineering skills. Often, there are good scientists and good software engineers. Working practises and priorities can be quite different, and these two groups don't always understand each other. Code that achieves excellent scientific results may not be able to run outside the computer on which it was developed, and well-implemented code may not give a scientifically relevant output. Both groups benefit greatly from working more closely together.
The BALTRAD partnership doesn't reinvent wheels unnecessarily. There is a certain category of scientist/developer who is categorically against anything she hasn't done herself. The results are commonly a reinvented wheel that's worse than the existing ones. That's not how we work, because reinventing wheels consumes resources unjustifiably. Using well-working wheels comes at the cost of trusting and integrating others' code, and this manifests itself in the form of third-party dependencies. But doing this is an acceptable cost in many cases as it saves time and money without compromising quality.
We believe in agile software development, without being agile purists, because doing so gives us higher-quality results.
We work with marketable skills. We use modern programming languages, software tools, and development infrastructure. Not only are we convinced that this leads to higher quality results, it also makes the development process more creative and fun. A seldom-mentioned yet related issue is that using marketable skills makes it easier to replace people should they leave, and this applies to both government and the private sector. We want to avoid painting ourselves into corners resulting from people who disappear, leaving behind them code that has been developed using obsolete or scarse skills.
We believe in Open Source principles, because we benefit more through sharing.
There are no requirements on hardware configuration or manufacturer, and we have no general preferences either. You can use our software on almost any hardware configuration: notebook, desktop, tower, rack, blade, virtual, probably also industrial hardware configurations.
Different partners have different hardware providers and different environments, so we have made an effort to create a system that will work for everyone.
In terms of performance, the simple answer is "it depends". If you are only interested in exchanging data, then entry-level hardware will be enough. Your hardware provider will have a more specific definition of entry-level but this normally involves a single CPU (dual- or quad-core), let's say 4 Gb RAM, 50 Gb of disk space for both the software and a few days of data, and an Ethernet adapter connected to a TCP/IP network. (Running BALTRAD over WiFi is probably not a good idea.) This hardware configuration assumes that it won't be used for anything else.
If you are interested in exchanging and processing large amounts of data, then the hardware requirements are still relatively modest. In this case, at least one quad-core CPU is needed. More RAM is required, probably at least 10 Gb. Disk space depends entirely on how much data you want to keep "alive" in the system at any given time, but a few hundred Gb is probably a safe bet. Disks in any kind of RAID configuration are highly recommended. Redundant Ethernet connections are a good idea.
If you want to create several redundant instances of the system running simultaneously, then we can recommend that they share redundant (RAIDed) disks from e.g. a Storage Area Network (SAN) that are used to store data.
We do not recommend you install and use our software over networked file systems like NFS because they have a tendency to cause significant performance bottlenecks.
Network bandwidth needs are notoriously difficult to determine because they depends on factors that we have difficulty quantifying. Internet bandwidth is pretty inexpensive these days, whereas dedicated network bandwidth can be costly (e.g. the RMDCN in Europe). We have no hard requirements, only experience. A 64 kbit/s network connection will probably be sufficient to support the exchange of data from a few radars, whereas a 10 Mbit/s connection might be enough to support the continental scale. There are uncertainties in these estimates that need more time to be clarified.
Any credible 64-bit Linux distribution will have no difficulty accommodating BALTRAD software. One of the distributions mentioned above in What operating systems does the software run on? will definitely work because it works for us already. The software will likely work on the 32-bit versions of the same distro, but some of the software's unit tests will fail.
The BALTRAD installation notes that accompany the software packages contain complete details on requirements. They are usually found in a text file called INSTALL.
A critical software requirement when using the system in real time is access to a Postgres database server version 8.3.9 or higher, preferably 8.4+. This database server does not need to be installed on the same server as the software is installed on, but it must be accessible. This requirement is not needed if you are not going to exchange any data but instead just process data off line.
Other required software can be managed with your distro's preferred package manager, e.g. RPM, yum, apt-get, etc.
You might also need to install additional packages since one or more modules depend on them:
Make sure you install 64-bit versions of these packages where they exist.
As mentioned above, we don't reinvent wheels unnecessarily and we have developed our software using C/C++, Java, and Python. We therefore have a set of dependencies that is probably larger than you are accustomed to. Note, however, that you do not have to download and install these yourself. Our installer does it for you.
Some of the BALTRAD software packages written in Java have included third-party dependencies and are managed by these packages. An example of this is the use of the Quartz Enterprise Job Scheduler.
Most Linux distributions already contain almost all of the packages in the table above, so you may be wondering why we don't use them. Versions may be different, and they may be built differently, e.g. without support for a feature we need. It's pretty likely that they'll will work, but we aren't taking any unnecessary risks by building known releases ourselves.
Our codebase comprises two different levels of packaging. When we address the BALTRAD system, we mean enterprise-grade software that has gone through all the development, implementation, validation, and integration steps required to be described as such. This code is tried, tested, and solid. It works together with the rest of the system as intended. The current packages that are part of the system are:
| Package | Environment | Description |
|---|---|---|
| baltrad-db | Python, Java | Database manager subsystem |
| BaltradDex | Java | Distribution and Exchange subsystem |
| baltrad_wms | OGC Map Server | Web map services |
| bbufr | C, Python | BALTRAD interface to EUMETNET OPERA's BUFR software |
| beamb | C, Python | Determination of, and correction for, beam blockage caused by topography |
| beast | Java | Task manager/scheduler subsystem |
| bRopo | C, Python | Anomaly (non-precipitation echo) detection and removal |
| GoogleMapsPlugin | Python | Creates PNG images for use with Google Maps |
| node-installer | Python | Installation wizard |
| OdimH5 | Java | Data injector using ODIM_H5 and Rainbow file formats |
| RAVE | C, Python | Product generation framework and toolbox. Injector using ODIM_H5 files. |
We also have lab software that has been developed in the project, and that hasn't yet made it into the system. These packages are in different stages of development, where they may already give high-quality scientific output but are not yet integrated with the system in a harmonized way, and other packages may still be being restructured. Such packages show promise and can be considered to be in the pipeline. These are currently:
| Package | Environment | Description |
|---|---|---|
| BALTRAD HMC | C | Dual-polarization hydrometeor classifier and attenuation correction |
| bRack | C++, Python | Anomaly detection and removal, product generation including injective compositing |
There are two ways to install the system. Either using the node installer faq_inst_node_installer or as packages How do you install rpm packages.
As of BALTRAD 3.0 we have started the work to allow the system to be installed using traditional package managers like rpm or debian packages. Currently we only have full support for installing BALTRAD as rpm:s. We also provide a yum repository that can be used to simplify the installation even further since yum will ensure that the necessary third party packages are installed. In the future we also hope that we will be able to provide the system as debian packages.
There are two basic approaches to install the software from the rpms. Either you download the rpm:s manually (from http://git.baltrad.eu/baltrad-packages/CentOS/7/5/) and install them with yum or you can add the baltrad-package.repo to your yum installation catalogue and install them that way.
The recommended approach is to use the yum-repository since that will provide information about updates.
To setup the yum-repo, you will have to login as root and do a number of steps. After that the installation and updates will hopefully be quite painless.
However, before we even atempt to install the baltrad packages, several dependencies has to be installed. The first thing you will have to do is to install the latest epel-release rpm which you can find here
Then you install the epel release rpm by typing
%> rpm -Uvh epel-release*.rpm
After that you should install postgres and the python 3.6 distributables available from the epel above.
%> yum install postgresql postgresql-devel postgresql-contrib postgresql-server %> yum install python36 python36-devel python36-libs python36-setuptools
As a final step you should update the yum repository with the repo file pointing at the baltrad packages.
%> cd /etc/yum.repos.d
%> wget http://git.baltrad.eu/baltrad-packages/CentOS/7/5/current/baltrad-package.repo
%> yum update
%> (install epel, see howtos)
%> yum install python36 python36-devel python36-libs python36-setuptools
%> yum install `yum list | grep baltrad-repo | awk '{print $1;}'`
In some cases you will have to expire the cache to be notified that new packages are available and that can be done by
%> yum clean expire-cache %> yum update
The node-installer package will install those parts of the system that you want to use. The node-installer should work on most linux-based operating systems. It can be used in the situations where there are no pre-built packages for your operating system.
This installation is done by downloading the node-installer package itself from http://git.baltrad.eu/git and downloading a snapshot, or the tarball from http://git.baltrad.eu/manual/releases.html. This is a small package.
$ tar xvzf node-installer.tar.gz
The software will unpack into a directory called "node-installer". After that, follow the instructions found in the INSTALL file.
Alternatively, use a Git client as is explained on the "BALTRAD releases" page:
$ git clone git://git.baltrad.eu/node-installer.git
Even in this case, the node-installer will download into a directory called "node-installer".
You will tell the node installer which system components you want to install and it will download, build, and install them, ensuring that all dependencies are resolved. The process is designed to be as "hands-off" as possible.
In practise, you will run the "setup" command with several options depending on what you want to install. An example installation might look like this:
$ ./setup --tomcatpwd=<password> --nodename=se.smhi.balthazar \ --prefix=/opt/baltrad --jdkhome=/usr/java/jdk1.6.0_16 \ --with-psql=/usr/include/pgsql,/usr/lib64/pgsql --dbpwd=<password> \ --with-rave --rave-dex-spoe=localhost:8080 \ --rave-center-id=<Your country's WMO originating center number> \ install
Don't forget to choose your passwords wisely, and put them in a safe place that you remember! Also, it's probably a good idea to set your node name using a systematic naming convention like the one above that is inspired by Java conventions.
There are many more options, and they can be listed by typing
$ ./setup --help
That's it, basically. When the software has been built, the node installer will install it and under the path defined by –prefix, and then the system will be started. More information can be found in the installation section of the User Guide, and of course in the node-installer's INSTALL file.
No, the modular nature of the system implies that you only install those packages containing the functionality you want to use.
For a real-time system, the basic system with no optional parts comprises the DEX, the BDB, and the Beast subsystems. The reason why there are no setup options like –with-dex is because this is a required subsystem.
This means that our software can be used for networking only, leaving the data processing functionality out alltogether if desired.
Yes and no. You need a network connection to fetch all the packages that need to be installed. The node installer itself is quite a small package, and it won't fetch anything you don't want to use, so the overall use of the web and your disk is kept to a minimum.
You can use the node installer to download all required packages but not install them, enabling them to be moved to another machine that is protected from the Internet behind a firewall before continuing with the real installation.
Normally, the node-installer will indicate if something went wrong. If all goes well, you can use your web browser. Type the system's URI in the address field. The default URI is localhost:8080, but you may have specified another one when you ran "setup". You should see a welcome page with a "Welcome to BALTRAD" message. All is well if you see this.
Change the admin user's password! In the web interface, log into the node for the first time using user "admin" and password "baltrad". Then go to Settings, User accounts, Edit, and in the list of users you'll see "admin" there and a link to change its password to the right.
According to How do you install the system?, go to the "bin" directory under the path that you defined by –prefix when you installed the system, and execute
[/opt/baltrad/bin]$ ./bltnode -all stop
We had to create some new indexes when upgrading to 1.1.0. This have the unfortunate side effect that if you have a lot of file entries it might cause your upgrade to fail. If you read this before you run into the problem it might be a good idea to clean the database from the data you don't need and perform the following command in psql.
baltrad=> analyze verbose bdb_nodes;
If you however read this after you got the failed upgrade, then you can try these steps out.
baltrad=> delete from bdb_files cascade where stored_date < 'YYYY-MM-DD'; removes all files older than YYYY-MM-DD baltrad=> analyze verbose bdb_nodes;
If you just want to get on the road again without caring about the old files.
baltrad=> truncate bdb_files, bdb_nodes, bdb_attribute_values;
We exchange polar data, either individual scans or polar volumes. We exchange any radar parameters, from conventional Doppler moments to those from dual-polarization systems. It's up to you to decide what you want to make available.
The quality of the polar data to exchange is another important issue that needs addressing. In BALTRAD we have defined the data that come out of the radar as the data to be exchanged. These data are not post-processed in any way prior to exchange. The underlying justification for doing this is that all data, both your own and those that your friends have sent you, are processed by your node, so you want to be able to treat them all on equal terms. For example, a user may want to analyze bird signatures. If someone has sent you data with these signals already filtered out, then you're in trouble. Another example is that processing prior to exchange in BALTRAD could lead to undocumented results, so you have no idea what has happened to the data prior to your receiving them. Because it is important in BALTRAD to keep track of data quality through the processing chain, we exchange basic data and then define our own processing chains according to our own needs. That having been said, no one is preventing you from requesting processed polar data from another node.
The file format used in BALTRAD, both for exchange and for processing, is ODIM_H5. This is the EUMETNET OPERA Data Information Model implementation with the HDF5 file format. Several radar manufacturers offer converters to ODIM_H5, as do some members of the community.
We do not (yet) accept any other file formats for exchange. All other formats must be converted to ODIM_H5 before they are injected into a BALTRAD node.
However, the data processing functionality in the RAVE package (BALTRAD toolbox) can read polar data in OPERA BUFR format.
People are experts in different areas, so the system we build together should let people contribute by doing what they do best. This should be done in a modular way, where subsystems communicate using methods that work no matter which of the agreed-upon programming languages is used.
The way we have designed the system is that subsystems communicate through messaging, using a set of well-defined message types and existing protocols. A given system component is thus synonymous with a service at an assigned port at an assigned IP number or address. Different subsystems can be physically located on different computers. This is good for balancing an overall computational load. It's also good for redundancy, giving high system resiliency.
We want a system that's easy to manage and use. That's why a lot of the administrator's functionality has been made accessible through a web-based user interface. Doing it this way is an easy way of bypassing IT policies that don't accomodate Linux on the desktop.
The system must scale to continental applications. When designing the system, we defined 175 radars as our target for scaling even though the project's partnership was much smaller. We are currently trialing our software at the European scale, so we will soon know how well our system does at it.
A lot more can be said about design; this just scratches the surface.
The system components and their interactions can be illustrated in the following.
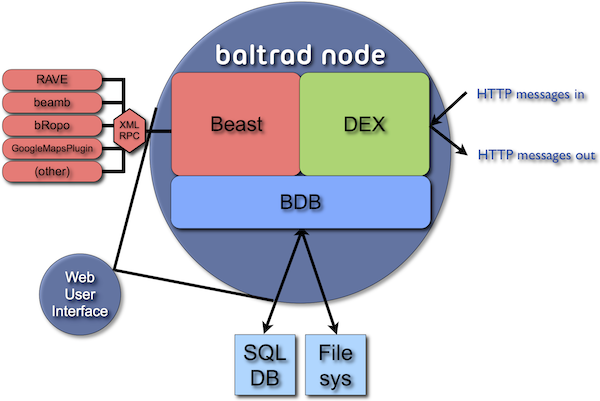
The subsystems can be identified by package above in What packages does BALTRAD software consist of today?
Communications between subsystems is performed using messaging over HTTP.
Communications between BALTRAD nodes is performed using the Distribution and Exchange (DEX) subsystem and MIME messages over HTTP. This system interacts with the BALTRAD Database (BDB) that provides a high-level interface between the BALTRAD node and the Postgre database server and file system containing ODIM_H5 files.
The Beast is also connected to the BDB, and this connection allows the Beast to schedule and run various tasks. The Beast operates using the concept of Adapters (how to do something) and Routes (the criteria that need to be satisfied in order to do the something specified by an adapter).
Data processing is performed through an XML-RPC adapter to the RAVE system, which is the product generation framework a.k.a. toolbox. RAVE relies on receiving messages from the Beast telling it what product to generate, how to generate it, and with which input data. RAVE will then either generate the product itself, or it will call the relevant package, e.g. beamb, to do it. Upon successful completion of the job, the resulting ODIM_H5 file is injected into the node through the DEX.
A wb-based user interface allows the user to configure and manage the node through a normal browser.
Yes, when you or other users access the web interface to interact with your node, the connection is secure.
Secure data exchange is achieved through the use of private and public DSA keys. When two nodes want to exchange data, no subscription to data can take place, and therefore no data transfer can start, unless the nodes have exchanged public keys. Presently, the exchange of these keys is performed manually by system administrators, through e-mail, telephone, snail-mail, pidgeon mail, messages in bottles, or the use of third-party certificate authorities, as they agree.
Even when we use the URI prefix "http" instead of "https", the connections are all still secure.
One. We refer to this port as the single point of entry. All communications to the node go through the SPOE.
Data injection is only relevant if you are going to use the system in real time. The first step is to convert your data to the ODIM_H5 file format. Several radar manufacturers provide converters, and members of the community do so too. In BALTRAD, the OdimH5 package contains a converter from a proprierary format to ODIM_H5, and the software can be expanded to convert from other formats.
When data have been converted to ODIM_H5, the next step is to inject them into your node. This can be done in two ways:
With either injector, the injection process involves secure handshaking with the node in the same way as when data are exchanged between nodes.
All data arrive to a node through the single point of entry, which is the only open port the system needs. This port is used by the DEX subsystem. The DEX will unpack the inbound message and extract the ODIM_H5 payload, forwarding it to the BDB where its contents are entered into the database. This is done by mining the ODIM metadata attributes and managing them in SQL tables, while the HDF5 files themselves are made accessible in a working cache directory where they are rotated. When this is done, the BDB notifies both the DEX and the Beast that the data are "available".
The DEX will then check to see if the data match any subscription criteria. If they do, then the data are transmitted to those nodes that have subscribed to them.
Simultaneously, the Beast will determine whether the newly-arrived data match any criteria defined for processing them. When such criteria have been satisfied, the Beast runs its job(s) itself or sends them to the RAVE system through an XML-RPC call. In either case, processed data (either in the form of quality-controlled data or derived products) are entered back into the system through the DEX, and the process repeats itself.
The following points summarize the procedure, but do not contain some necessary detail. Please see the User Guide for these details.
Note that data are pushed safely from originating node to recipient node after the subscription has been set up. The originating node decides which recipient nodes are entitled to subscribe to which data. The remote node that wishes to subscribe to data only subscribes to those data that it is given permission to subscribe to. This done through a mechanism called selective catalog exposure. And the receiving node ensures that nothing is pushed to it that it hasn't asked for.
The manual parts of data subscription, ie. configuring the public keys, may be automated in future system versions.
Yes, but you probably won't need the node software itself because its primary task is to take care of data exchange with other nodes. Off-line use is more related to processing the data, in which case the BALTRAD toolbox is probably what you're interested in.
In this case, you can install the RAVE package with its dependencies. You can also install the other data processing modules that use RAVE as a dependency. These packages can be used and completely off line, with no connection to any BALTRAD node. The RAVE package allows users to work with data interactively through a Python interpreter, as well as running binaries on the command line.
Any other package that is designed for command-line use will not need and connection to a running node, and will therefore be useable off line.
Start by taking a look at your code before looking at ours. Algorithms should be written in C or C++, although we haven't closed the door completely on Fortran.
Does your code separate the reading/writing of files from the functionality that processes the data? We want as clear a separation as possible because we want to combine different algorithms from different contributors in memory. To achieve this, we use the same read/write functionality for all data, through the RAVE package's C API to the ODIM_H5 file format. The concept looks like this:
When this is achieved, the separation between the file I/O and the algorithm itself means we can chain different algorithms in memory, and minimizing unnecessary reading/writing of files is a great way of improving performance. Doing this is also a great way of off-loading the responsibility of managing the file I/O on us, and this helps you focus on the science. An additional advantage of this is that we can be confident that the file I/O will always give consistent results, so the risk of people writing non-compliant ODIM_H5 is minimized.
This procedure implies that you use our file I/O routines as a dependency, but you control your algorithm. If you are thinking of implementing a new algorithm from scratch, consider taking a look at the C APIs in RAVE. They are modeled around ODIM_H5 and are designed to help manipulate polar volume, polar scan, polar scan parameter, Cartesian, and other objects at a fairly intuitive level. These include accurate coordinate transforms using the PROJ.4 projections library in the background.
You can stop there and contribute your results. Or you can continue. Preferably, we want the low-level languages for their performance and then write a wrapper to a high-level language Python or Java to manage the algorithm more easily. We're pretty good at this, so we can either do it or help you do it.
There is no direct visualization in our node software. Instead, we have packages that generate output that can be used with Google Maps or Web Map Services. There is a small exception to this, where you can use the user interface to the node to create simple PPI output of individual scans.
This is a conscious decision in BALTRAD. Different partners use different visualization systems, and these are often subject to strict policy that we don't want to mess with, so we don't.
In off-line mode, you can use the command-line tool "show" to create very simple screen plots, so-called "quick looks" of radar datasets. "show" reads ODIM_H5 data and displays a given radar variable or quality field based on its path in the file, defaulting to /dataset1/data1/data. For example, the reflectivity in the lowest scan of a polar volume (containing rain and also lots of contaminated sectors from external emitters) would be shown like this
$ show -i file.h5
and the result would be this window, where the top-left corner is the start of the ray pointing north, and each row is a new ray scanning clockwise. This is a typical B-scan display. Pressing the 'h' key gives you a list of simple things you can do with this window.

You can also use "show" to show Cartesian products. Note, however, that you need Python with PyGTK (Python interface to the GIMP Toolkit) to use "show". Any credible Linux distribution will have this already.
However, since the baltrad installation does not include installation of pygtk you will have to manage that operation yourself. One easy way is to make sure that you get pygtk installated on your system python interpreeter and then copy pygtk.py and pygtk.pth into the python site-packages directory of the baltrad installation. Then modify pygtk.pth to point at the proper location. Another way is to install pygtk into the baltrad python installation but that is left to the user to try.
By installing the RAVE package, you can access the toolbox on the command line and also from within a Python interpreter. The latter makes working with the toolbox interactive, which makes tasks like prototyping new algorithms quicker and more efficient. Taking the polar data illustrated in the plot above, the following simple example shows you how the toolbox functionality is used to read ODIM_H5 data, and how the toolbox objects are modelled after ODIM_H5. The following example shows how we access the only quality dataset in the volume's lowest scan; this quality field contains the probability of non-precipitation based on a set of anomaly detectors from the bRopo package.
$ python
Python 2.6.4 (r264:75706, Jan 5 2012, 19:49:31)
[GCC 4.1.2 20080704 (Red Hat 4.1.2-48)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import _raveio, rave_ql
>>> io_container = _raveio.open('pvol.h5')
>>> polar_volume = io_container.object
>>> first_scan = polar_volume.getScan(0)
>>> quality_field = first_scan.getQualityField(0)
>>> data = quality_field.getData()
>>> rave_ql.ql(data)
and "ql" will give the following view of the quality field, where cold colors show low probabilities and warm colors show high ones. Note, however, that you need Python with PyGTK (Python interface to the GIMP Toolkit) to do this.

As an alternative to doing this interactively, you can write scripts that do the same thing.
With difficulty, at least at the moment. To do this, you could use RAVE with a version of Python that contains SciPy, and use the plotting functionality in it. Or you roll your own interface another way using data read from ODIM_H5 files. We welcome such a contribution!
The community will live on. The partnership's cooperation is regulated through the BALTRAD Cooperation Agreement which contains mechanisms designed to safeguard the day-to-day maintenance and continued development of the network and the software system. Want to be part of this community-based weather radar networking? Get in touch.
 1.9.1 for
1.9.1 for 